“Python实现ElasticSearch的增删改查、聚合和集群监控”的版本间的差异
(→Python实现ElasticSearch的增删改查、聚合和集群监控) |
(→Python实现ElasticSearch的增删改查、聚合和集群监控) |
||
| (未显示另一用户的1个中间版本) | |||
| 第101行: | 第101行: | ||
'''ElasticSearch的CURD操作''' | '''ElasticSearch的CURD操作''' | ||
| + | |||
| + | |||
CURD解释:它代表创建(Create)、 更新 (Update) 、读取(Retrieve) 和删除(Delete)操作,主要被用在描述软件系统中DataBase或者持久层的基本操作功能 | CURD解释:它代表创建(Create)、 更新 (Update) 、读取(Retrieve) 和删除(Delete)操作,主要被用在描述软件系统中DataBase或者持久层的基本操作功能 | ||
| − | 不带密码访问: curl -XGET -u admin:password 'http://39.101.189.249:9200/_license' | + | 不带密码访问: curl -XGET -u admin:password 'http://39.101.189.249:9200/_license'<br> |
[[文件:2020-08-09 172022.png]] | [[文件:2020-08-09 172022.png]] | ||
| 第159行: | 第161行: | ||
运行结果: | 运行结果: | ||
[[文件:2020-08-09 174916.png]] | [[文件:2020-08-09 174916.png]] | ||
| + | |||
| + | 新增: | ||
| + | |||
| + | body_ add={"name" : "nick","city":"cs"} | ||
| + | es. index( index= ' ccdd', body=body_ add) | ||
| + | |||
| + | 删除数据: | ||
| + | es.delete(index='heart',id='1') | ||
| + | |||
| + | '''聚合查询''' | ||
| + | |||
| + | #!/usr/bin/env python3 | ||
| + | # @Author : knight | ||
| + | #1.建立连接 | ||
| + | from elasticsearch import Elasticsearch | ||
| + | es = Elasticsearch("172.20.128.31:9200") | ||
| + | #创建索引 | ||
| + | # res = es.indices. create(index= 'xxoo) | ||
| + | #插入数据 | ||
| + | body_ add={"name" : "nick" , "age" :"10"} | ||
| + | body_ add_ 2={"name" :"tom" , "age" :"20" } | ||
| + | body_ add_ 3={"name" :"rose","age" :"30"} | ||
| + | body_ add_ 4={"alice" :"rose" , "age" :"25"} | ||
| + | es . index( index=' xx0o ' , body=body_ add) | ||
| + | es . index(index= ' xx0o ',body=body_ add_ 2) | ||
| + | es . index( index= ' xxoo' , body=body_ _add_ 3) | ||
| + | es . index( index= ' xxoo',body=body_ _add_ _4) | ||
| + | |||
| + | #获取最小的年龄 | ||
| + | res = es.search(index='test6', body = { | ||
| + | "query": { | ||
| + | "match_all": {} | ||
| + | }, | ||
| + | "aggs": { | ||
| + | "min_age": { | ||
| + | "min": { | ||
| + | "field": "age" | ||
| + | } | ||
| + | } | ||
| + | } | ||
| + | }) | ||
| + | print(res['aggregations']['min_age']['value']) | ||
| + | |||
| + | |||
| + | #获取最大的年龄 | ||
| + | res = es.search(index='test6', body = { | ||
| + | "query": { | ||
| + | "match_all": {} | ||
| + | }, | ||
| + | "aggs": { | ||
| + | "max_age": { | ||
| + | "max": { | ||
| + | "field": "age" | ||
| + | } | ||
| + | } | ||
| + | } | ||
| + | }) | ||
| + | print(res['aggregations']['max_age']['value']) | ||
| + | |||
| + | |||
| + | #获取年龄和 | ||
| + | res = es.search(index='test6', body = { | ||
| + | "query": { | ||
| + | "match_all": {} | ||
| + | }, | ||
| + | "aggs": { | ||
| + | "sum_age": { | ||
| + | "sum": { | ||
| + | "field": "age" | ||
| + | } | ||
| + | } | ||
| + | } | ||
| + | }) | ||
| + | print(res['aggregations']['sum_age']['value']) | ||
| + | |||
| + | |||
| + | #获取平均年龄 | ||
| + | res = es.search(index='test6', body = { | ||
| + | "query": { | ||
| + | "match_all": {} | ||
| + | }, | ||
| + | "aggs": { | ||
| + | "avg_age": { | ||
| + | "avg": { | ||
| + | "field": "age" | ||
| + | } | ||
| + | } | ||
| + | } | ||
| + | }) | ||
| + | print(res['aggregations']['avg_age']['value']) | ||
| + | # from、size | ||
| + | #from:从“第几条”开始查询, size:查询多少条 | ||
| + | res = es.search(index='test6', body = { | ||
| + | "query": { | ||
| + | "match_all": {} | ||
| + | }, | ||
| + | "size": 1, | ||
| + | "from": 2 | ||
| + | }) | ||
| + | print(res) | ||
2020年8月9日 (日) 14:06的最新版本
Python实现ElasticSearch的增删改查、聚合和集群监控
ElasticSearch时是什么,ElasticSearch是非常强大软件,它不仅仅只是应用在ELK上面,它还可以做Mysq等关系型数据库的横向扩展,它还可以作为像百度一样的搜索引擎, 它还可以高效地做敏感词的过滤,它也可以处理大数据的应用,等等。ElasticSearch是Elastic家族的-款产品。而Elastic家族 下面有很多的产品比如有Logstash, Beats, Kibana等等
ElasticSearch介绍
Elasticsearch是一个开源的分布式、 RESTful 风格的搜索和数据分析引擎,它的底层是开源库Apache Lucene。Lucene可以说是当下最先进、高性能、全功能的搜索引|擎库一无论是开源还是私有,但它也仅仅只是一个库。为了充分发挥其功能,你需要使用Java并将Lucene直接集成到应用程序中。更糟糕的是, 您可能需要获得信息检索学位才能了解其工作原理,因为Lucene非常复杂。为了解决Lucene使用时的繁复性,于是Elasticsearch便应运而生。 它使用Java编写,内部采用Lucene做索引与搜索,但是它的目标是使全文检索变得更简单,简单来说,就是对Lucene做了一层封装,它提供了一套简单一致的RESTful API来帮助我们实现存储和检索。
ElasticSearch安装
ElasticSearch官方文档: https://www.elastic.co/cn/downloads ElasticSearch软件下载地址:https://www.elastic.co/downloads
首先配置好java环境 测试命令:java -version

环境准备防止往后报错: 修改文件限制 vim /etc/security/limits.conf
#增加的内容 * soft nofile 262144 * hard nofile 262144 * soft nproc 262144 * hard nproc 262144 #锁内存 * soft memlock unlimited * hard memlock unlimited
调整虚拟内存&最大并发连接 vim /etc/sysctl.conf
#增加的内容 vm.max_map_count=262144 fs.file-max=262144
用root账号执行“sysctl -p”
官网下载好安装包后上传到linux使用xftp或者rz命令,到home目录下
进入到elasticsearch-6.3.4 目录下 编辑配置文件:vim config/elasticsearch.yml
cluster.name: es-zegopay node.name: es-1.1 path.data: /elk/es/data path.logs: /elk/es/logs bootstrap.memory_lock: true network.host: 0.0.0.0 http.port: 9200
配置项说明:
项 说明 cluster.name 集群名 node.name 节点名 path.data 数据保存目录 path.logs 日志保存目录 network.host 节点host/ip http.port HTTP访问端口 bootstrap.memory_lock 锁定内存(要相应更改/etc/security/limits.conf文件) discovery.seed_hosts 集群中种子节点的初始列表,启动时使用这个列表进行探测 cluster.initial_master_nodes 集群初始化的主节点列表
创建ELK专用用户(Elasticsearch不能用root用户启动)
- 创建ELK APP目录: mkdir /usr/local/elk
- 创建ELK 数据目录: mkdir /elk
- 创建Elasticsearch主目录: mkdir /elk/es
- 创建Elasticsearch数据目录: mkdir /elk/es/data
- 创建Elasticsearch日志目录: mkdir /elk/es/logs
创建elsearch用户组: groupadd elsearch
创建elsearch加入到组:useradd elsearch -g elsearch -p elasticsearch
更改elasticsearch-6.4.2文件夹及内部文件的所属用户及组为elsearch:elsearch:chown -R elsearch:elsearch elasticsearch-6.4.2
赋予elk权限:chown -R elsearch:elsearch /elk
切换到elsearch用户再启动 su elsearch cd elasticsearch-6.4.2/bin sh elasticsearch &

启动成功后打开浏览器输入ip+9200:
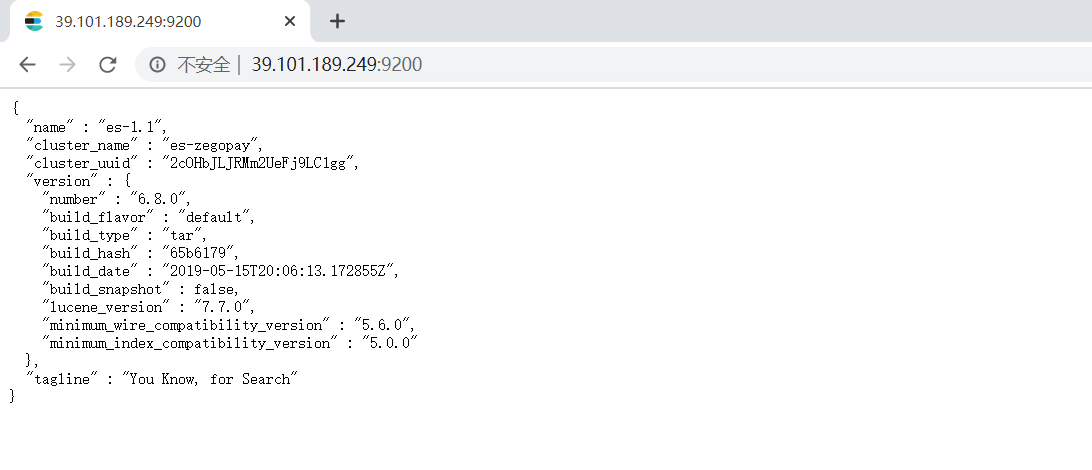

搭建过程中出现的问题:
有可能出现启动成功,1分钟后自动killed,没有回显错误信息,就是看日志也没有错误,这可能就是服务器的内存不足,由于ES是运行在JVM上,JVM本身除了分配的heap内存以外,还会用到一些堆外(off heap)内存。 在小内存的机器上跑ES,如果heap划分过多,累加上堆外内存后,总的JVM使用内存量可能超过物理内存限制。 如果swap又是关闭的情况下,就会被操作系统oom killer杀掉。
修改ES中config目录下的jvm.options文件
vim jvm.options
将
-Xms1g
-Xmx1g
改为
-Xms512m
-Xmx512m
就启动成功了
ElasticSearch的CURD操作
CURD解释:它代表创建(Create)、 更新 (Update) 、读取(Retrieve) 和删除(Delete)操作,主要被用在描述软件系统中DataBase或者持久层的基本操作功能
不带密码访问: curl -XGET -u admin:password 'http://39.101.189.249:9200/_license'

创建索引:
curl -XPUT '39.101.189.249:9200/heart?pretty'
查询所有索引以及数据大小:
curl '39.101.189.249:9200/_cat/indices?v'
向指定索引新增文档:
curl -XPUT '39.101.189.249:9200/heart/_doc/1' -H 'Content-Type:application/json' -d'{
> "user":"tom",
> "message":"hello world"
> }'
查询索引下的全部文档:
curl -XGET 39.101.189.249:9200/heart/_search | jq

删除文档:
curl -XDELETE 39.101.189.249:9200/heart/_doc/1
使用Python操作ElasticSearch
我们使用Python3的版本,先安装对应的es库
pip3 install elasticsearch
索引操作
#coding:utf-8
# @Author : knight
#1.建立连接
from elasticsearch import Elasticsearch
es = Elasticsearch("172.26.142.43:9200")
#创建索引
res = es.indices.create(index='abc')
#显示索引列表
indices = es.indices.get_alias()
print(indices)
#删除索引
res = es.indices.delete(index='abc')
运行结果如下:

查询操作:
#coding:utf-8
from elasticsearch import Elasticsearch
es = Elasticsearch("172.26.142.43:9200") #无密码访问
indices = es.indices.get_alias() #显示索引列表
print(indices)
res = es.search(index="heart") #查询heart索引数据
aa = es.get(index="heart",id="1")
print(aa)
运行结果:

新增:
body_ add={"name" : "nick","city":"cs"}
es. index( index= ' ccdd', body=body_ add)
删除数据:
es.delete(index='heart',id='1')
聚合查询
#!/usr/bin/env python3
# @Author : knight
#1.建立连接
from elasticsearch import Elasticsearch
es = Elasticsearch("172.20.128.31:9200")
#创建索引
# res = es.indices. create(index= 'xxoo)
#插入数据
body_ add={"name" : "nick" , "age" :"10"}
body_ add_ 2={"name" :"tom" , "age" :"20" }
body_ add_ 3={"name" :"rose","age" :"30"}
body_ add_ 4={"alice" :"rose" , "age" :"25"}
es . index( index=' xx0o ' , body=body_ add)
es . index(index= ' xx0o ',body=body_ add_ 2)
es . index( index= ' xxoo' , body=body_ _add_ 3)
es . index( index= ' xxoo',body=body_ _add_ _4)
- 获取最小的年龄
res = es.search(index='test6', body = {
"query": {
"match_all": {}
},
"aggs": {
"min_age": {
"min": {
"field": "age"
}
}
}
})
print(res['aggregations']['min_age']['value'])
- 获取最大的年龄
res = es.search(index='test6', body = {
"query": {
"match_all": {}
},
"aggs": {
"max_age": {
"max": {
"field": "age"
}
}
}
})
print(res['aggregations']['max_age']['value'])
- 获取年龄和
res = es.search(index='test6', body = {
"query": {
"match_all": {}
},
"aggs": {
"sum_age": {
"sum": {
"field": "age"
}
}
}
})
print(res['aggregations']['sum_age']['value'])
- 获取平均年龄
res = es.search(index='test6', body = {
"query": {
"match_all": {}
},
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
}
}
})
print(res['aggregations']['avg_age']['value'])
# from、size
#from:从“第几条”开始查询, size:查询多少条
res = es.search(index='test6', body = {
"query": {
"match_all": {}
},
"size": 1,
"from": 2
})
print(res)