深度学习入门
目录
深度学习案例
- 神经网络:https://baijiahao.baidu.com/s?id=1618523948331231188&wfr=spider&for=pc
- 深度学习:https://baijiahao.baidu.com/s?id=1618523948331231188&wfr=spider&for=pc
深度学习应用
20个令人惊叹的深度学习应用:https://www.sohu.com/a/298212922_100225419
飞将实验列表:https://aistudio.baidu.com/aistudio/projectoverview/public/2
手写数字识别
课程4-深度学习入门CV-手写数字识别:https://aistudio.baidu.com/aistudio/projectdetail/78958
影像分析
PaddleHub 肺炎CT影像分析:https://aistudio.baidu.com/aistudio/projectdetail/444580?forkThirdPart=1
猫狗识别
CNN猫狗识别:猫狗识别0612 https://aistudio.baidu.com/aistudio/projectdetail/70543
文本分类
文本分类:https://aistudio.baidu.com/aistudio/projectdetail/90231
其他
手把手带你吃透深度学习:https://aistudio.baidu.com/aistudio/projectdetail/325575
使用Python进行机器学习(ski-learn):https://aistudio.baidu.com/aistudio/projectdetail/98035
深度学习原理
训练前准备
这个教程的目标读者是对机器学习和TensorFlow都不太了解的新手。
当我们开始学习编程的时候,第一件事往往是学习打印"Hello World"。就好比编程入门有Hello World,机器学习入门有MNIST。
MNIST是一个入门级的计算机视觉数据集,它包含各种手写数字图片:

它也包含每一张图片对应的标签,告诉我们这个是数字几。比如,上面这四张图片的标签分别是5,0,4,1。
在此教程中,我们将训练一个机器学习模型用于预测图片里面的数字。我们的目的不是要设计一个世界一流的复杂模型 -- 尽管我们会在之后给你源代码去实现一流的预测模型 -- 而是要介绍下如何使用TensorFlow。所以,我们这里会从一个很简单的数学模型开始,它叫做Softmax Regression。
对应这个教程的实现代码很短,而且真正有意思的内容只包含在三行代码里面。但是,去理解包含在这些代码里面的设计思想是非常重要的:TensorFlow工作流程和机器学习的基本概念。因此,这个教程会很详细地介绍这些代码的实现原理。
准备工作
- 在下载数据之前,需要在你的Linux系统中安装python-numpy、python-six、python-pip、python-dev、tensorflow等包。
参考文档:[ubuntu/linux系统下tensorflow的安装 https://jingyan.baidu.com/article/455a99504fb489a1662778b8.html]
下载数据
- MNIST数据集的官网是Yann LeCun's website。在这里,我们提供了一份python源代码用于自动下载和安装这个数据集。
- 源代码在GitHub上,下
使用方法
- 将以上代码存为input_data.py文件
- 新建test.py文件,与input_data.py在同一工程目录下
- test.py内容(略)
- 运行test.py文件:
python test.py
- 这时可以看到在同一目录下多了一个data目录,这就是下载的数据集:
MNIST数据集
下载下来的数据集被分成两部分:60000行的训练数据集(mnist.train)和10000行的测试数据集(mnist.test)。这样的切分很重要,在机器学习模型设计时必须有一个单独的测试数据集不用于训练而是用来评估这个模型的性能,从而更加容易把设计的模型推广到其他数据集上(泛化)。
正如前面提到的一样,每一个MNIST数据单元有两部分组成:一张包含手写数字的图片和一个对应的标签。我们把这些图片设为“xs”,把这些标签设为“ys”。训练数据集和测试数据集都包含xs和ys,比如训练数据集的图片是 mnist.train.images ,训练数据集的标签是 mnist.train.labels。
训练集中的每一张图片包含28像素X28像素。我们可以用一个数字数组来表示这张图片:

跟我们用手机拍摄的图片类似,这些小图片拥有28x28 = 784个像素,或784个向量空间。从这个角度来看,MNIST数据集的图片就是在784维向量空间里面的点。
因此,在MNIST训练数据集中,mnist.train.images 是一个形状为 [60000, 784] 的张量,第一个维度数字用来索引图片,第二个维度数字用来索引每张图片中的像素点。在此张量里的每一个元素,都表示某张图片里的某个像素的强度值,值介于0和1之间。

相对应的MNIST数据集的标签是数字,用来描述给定图片里的数字是几?可选的值是0~9。比如,标签0将表示成([1,0,0,0,0,0,0,0,0,0,0]),标签9将表示成([0,0,0,0,0,0,0,0,0,0,1])。因此, mnist.train.labels 是一个 [60000, 10] 的数字矩阵。

好了,我们准备好可以开始构建我们的模型啦!
开始训练
Softmax回归介绍
我们知道MNIST的每一张图片都表示一个数字,从0到9。我们希望得到给定图片代表每个数字的概率。比如说,我们的模型可能推测一张包含9的图片代表数字9的概率是80%但是判断它是8的概率是5%(因为8和9都有上半部分的小圆),然后给予它代表其他数字的概率更小的值。
这是一个使用softmax回归(softmax regression)模型的经典案例。softmax模型可以用来给不同的对象分配概率。好了,那么概率又是什么东东?你可以把它看作是实现某件事情的可能性,如足彩中,鲁能泰山队赢上海上港的概率为50%,平和输的概率分别为30%、20%。
softmax回归(softmax regression)分两步:
第一步:为了得到一张给定图片属于某个特定数字类的证据(evidence),我们对图片像素值进行加权求和,求出的和越大,代表它属于某个数字的证据越大
比如说,对于给定的输入图片 x 它代表的是数字 i 的证据可以表示为:

其中j 代表给定图片 x 的像素索引用于像素求和,xj代表该像素的像素值(0~1),Wi 代表权重,, bi代表数字 i 类的偏置量,
<p如果这个像素具有很强的证据说明这张图片不属于该类,那么相应的权值为负数,相反如果这个像素拥有有利的证据支持这张图片属于这个类,那么权值是正数。而最后我们加入一个额外的偏置量bi的原因是,因为输入往往会带有一些无关的干扰量。</p> 这就好像一群在体育场看台上举牌子的观众在猜他们举得的是什么图案,有人说是1,有人说不是1,有人说有点像1.
第二步,我们用softmax函数可以把这些证据转换成概率 y:

这里的softmax可以看成是一个激励(activation)函数或者链接(link)函数,把我们定义的线性函数的输出转换成我们想要的格式,也就是关于10个数字类的概率分布。因此,给定一张图片,它对于每一个数字的吻合度可以被softmax函数转换成为一个概率值。
总结
对于softmax回归模型可以用下面的图解释,对于输入的xs加权求和,再分别加上一个偏置量,最后再输入到softmax函数中:

如果我们学过线性代数,也可以把它表示为:

注意,W的维度是[784,10],因为我们想要用784维的图片向量乘以它以得到一个10维的证据值向量,每一位对应不同数字类。b的形状是[10],所以我们可以直接把它加到输出上面。
实现模型
现在,我们可以实现我们的模型啦。只需要一行代码!
y = tf.nn.softmax(tf.matmul(x,W) + b)
- 首先,我们用tf.matmul(X,W)表示x乘以W,对应之前等式里面的Wx,这里x是一个2维张量拥有多个输入。然后再加上b,把和输入到tf.nn.softmax函数里面。
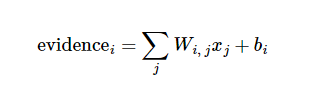
至此,我们先用了几行简短的代码来设置变量,然后只用了一行代码来定义我们的模型。TensorFlow不仅仅可以使softmax回归模型计算变得特别简单,它也用这种非常灵活的方式来描述其他各种数值计算,从机器学习模型对物理学模拟仿真模型。一旦被定义好之后,我们的模型就可以在不同的设备上运行:计算机的CPU,GPU,甚至是手机!
训练模型
理论1:成本函数
为了训练我们的模型,我们首先需要定义一个指标来评估这个模型是好的。其次,在机器学习,我们通常定义指标来表示一个模型是坏的,这个指标称为成本(cost)或损失(loss),然后尽量最小化这个指标。但是,这两种方式是相同的。
一个非常常见的,非常漂亮的成本函数是“交叉熵”(cross-entropy)。交叉熵产生于信息论里面的信息压缩编码技术,但是它后来演变成为从博弈论到机器学习等其他领域里的重要技术手段。它的定义如下:

y 是我们预测的概率分布, y' 是实际的分布(我们输入的one-hot vector)。比较粗糙的理解是,交叉熵是用来衡量我们的预测用于描述真相的低效性。更详细的关于交叉熵的解释超出本教程的范畴,但是你很有必要好好理解它。
- 以下关于交叉熵的解释出自:https://www.zhihu.com/question/41252833


为了计算交叉熵,我们首先需要添加一个新的占位符用于输入正确值:
y_ = tf.placeholder("float", [None,10])
然后我们可以用 计算交叉熵:
计算交叉熵:
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
首先,用 tf.log 计算 y 的每个元素的对数。接下来,我们把 y_ 的每一个元素和 tf.log(y_) 的对应元素相乘。最后,用 tf.reduce_sum 计算张量的所有元素的总和。(注意,这里的交叉熵不仅仅用来衡量单一的一对预测和真实值,而是所有100幅图片的交叉熵的总和。对于100个数据点的预测表现比单一数据点的表现能更好地描述我们的模型的性能。
(注意,这里的交叉熵不仅仅用来衡量单一的一对预测和真实值,而是所有100幅图片的交叉熵的总和。对于100个数据点的预测表现比单一数据点的表现能更好地描述我们的模型的性能。.
下面我们要做的是什么呢 ?通过一种方法是我们的成本函数-交叉熵最小
幸运的是,数学上已经提供了梯度下降的方法来解决它。
#backpropagation algorithm train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
理论2:反向传播算法
- 现在我们知道我们需要我们的模型做什么啦,用TensorFlow来训练它是非常容易的。因为TensorFlow拥有一张描述你各个计算单元的图,它可以自动地使用反向传播算法(backpropagation algorithm)来有效地确定你的变量是如何影响你想要最小化的那个成本值的。然后,TensorFlow会用你选择的优化算法来不断地修改变量以降低成本。
- 反向传播算法(Backpropagation)是目前用来训练人工神经网络(Artificial Neural Network,ANN)的最常用且最有效的算法。其主要思想是:
(1)将训练集数据输入到ANN的输入层,经过隐藏层,最后达到输出层并输出结果,这是ANN的前向传播过程; (2)由于ANN的输出结果与实际结果有误差,则计算估计值与实际值之间的误差,并将该误差从输出层向隐藏层反向传播,直至传播到输入层; (3)在反向传播的过程中,根据误差调整各种参数的值;不断迭代上述过程,直至收敛

- 具体到Tensorflow,它可以使用一行代码就可以实现反向传播代码:
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
- 在这里,我们要求TensorFlow用梯度下降算法(gradient descent algorithm)以0.01的学习速率最小化交叉熵。梯度下降算法(gradient descent algorithm)是一个简单的学习过程,TensorFlow只需将每个变量一点点地往使成本不断降低的方向移动。当然TensorFlow也提供了其他许多优化算法:只要简单地调整一行代码就可以使用其他的算法。
- TensorFlow在这里实际上所做的是,它会在后台给描述你的计算的那张图里面增加一系列新的计算操作单元用于实现反向传播算法和梯度下降算法。然后,它返回给你的只是一个单一的操作,当运行这个操作时,它用梯度下降算法训练你的模型,微调你的变量,不断减少成本。
开始训练
- 现在,我们已经设置好了我们的模型。在运行计算之前,我们需要添加一个操作来初始化我们创建的变量:
init = tf.initialize_all_variables()
- 现在我们可以在一个Session(对话)里面启动我们的模型,并且初始化变量:
sess = tf.Session() sess.run(init)
- 然后开始训练模型,这里我们让模型循环训练1000次!
for i in range(1000):
batch_xs, batch_ys = mnist.train.next_batch(100)
sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
- 该循环的每个步骤中,我们都会随机抓取训练数据中的100个批处理数据点,然后我们用这些数据点作为参数替换之前的占位符来运行train_step。
- 使用一小部分的随机数据来进行训练被称为随机训练(stochastic training)- 在这里更确切的说是随机梯度下降训练。在理想情况下,我们希望用我们所有的数据来进行每一步的训练,因为这能给我们更好的训练结果,但显然这需要很大的计算开销。所以,每一次训练我们可以使用不同的数据子集,这样做既可以减少计算开销,又可以最大化地学习到数据集的总体特性。
评估模型
- 那么我们的模型性能如何呢?
- 首先让我们找出那些预测正确的标签。tf.argmax 是一个非常有用的函数,它能给出某个tensor对象在某一维上的其数据最大值所在的索引值。由于标签向量是由0,1组成,因此最大值1所在的索引位置就是类别标签,比如tf.argmax(y,1)返回的是模型对于任一输入x预测到的标签值,而 tf.argmax(y_,1) 代表正确的标签,我们可以用 tf.equal 来检测我们的预测是否真实标签匹配(索引位置一样表示匹配)。
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
- 这行代码会给我们一组布尔值。为了确定正确预测项的比例,我们可以把布尔值转换成浮点数,然后取平均值。例如,[True, False, True, True] 会变成 [1,0,1,1] ,取平均值后得到 0.75.
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
- 最后,我们计算所学习到的模型在测试数据集上面的正确率。
print sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})
- 这个最终结果值应该大约是91%。
- 这个结果好吗?嗯,并不太好。事实上,这个结果是很差的。这是因为我们仅仅使用了一个非常简单的模型。不过,做一些小小的改进,我们就可以得到97%的正确率。最好的模型甚至可以获得超过99.7%的准确率!(想了解更多信息,可以看看这个关于各种模型的性能对比列表。)
- 比结果更重要的是,我们从这个模型中学习到的设计思想。不过,如果你仍然对这里的结果有点失望,可以查看下一个教程,在那里你可以学习如何用FensorFlow构建更加复杂的模型以获得更好的性能!
参考文档:
- [1] MNIST机器学习入门 http://www.tensorfly.cn/tfdoc/tutorials/mnist_beginners.html
- [2] TensorFlow下MNIST数据集下载脚本input_data.py http://blog.csdn.net/lwplwf/article/details/54896959