解析岗位列表页源代码
岗位列表页的结构
定制基于Java的WebMagic爬虫框架抓取51job官网上根据关键词“云计算”搜索出的岗位结果。打开51job网页搜索“云计算”,显示出来的岗位结果信息页的结构,如图3-2所示。这是搜索结果的首页,也是爬虫抓取的起始页。可以通过添加后续链接的URL至爬取队列,使得爬虫按照要求一步步循序下去。这里需要添加的链接便是具体岗位的信息页,以及后续列表分页。

图3-2 岗位列表页结构
爬取步骤
基本设置
这是在WebMagic框架中的PageProcessor组件中定制实现的,首先要做的是设置抓取的基本配置,包括编码、抓取间隔、重试次数,代码如下:
private Site site = Site.me().setRetryTimes(3).setSleepTime(10).setCharset("gbk");
这里选择重试次数为3次,抓取间隔为10毫秒,编码根据为51job网页源代码可以查看得到,如下所示:
<html> <head> <meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"> <meta http-equiv="Content-Type" content="text/html; charset=gbk"> <link rel="icon" href="/favicon.ico" type="image/x-icon"/> <title>【云计算招聘,求职】-前程无忧</title>
该招聘网站的编码为gbk。
爬取页面
接下来,判断当前分析的页面是否为岗位列表页。不难发现,列表页的URL中都含有search.51job.com字符段,可以通过简单的if语句判断:
if (page.getUrl().toString().contains("search.51job.com"))
分析页面
下面分析岗位信息页链接的HTML源代码,并用Xpath语法解析出,添加至抓取队列。
检查某个链接源代码的方法,在岗位列表中右击一项,在弹出的下拉菜单中选择“Inspect”命令,如图3-3所示。
图3-3 选择Inspect命令
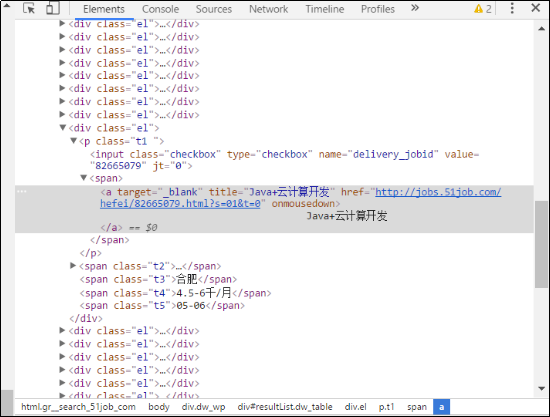
右击并选择检查(Inspect)后,出现了该链接的HTML源码,如图3-4所示。

{kind=link}
图3-4 查看HTML源代码
标签下的唯一的超链接,该标签的class名为t1。同理,这个岗位列表页下的所有岗位信息页的URL都有着相同的格式。因此可以使用Xpath全部识别,并添加至抓取队列,(谷歌浏览器 右键点击元素,然后检查,然后在相应代码上点击右键,Copy -> Copy XPath 可以复制 Xpath内容 可查看元素详情P).代码实现如下: select = page.getHtml().xpath("//p[@class='t1']"); urls = select.links().all(); page.addTargetRequests(urls); 添加后续分页的链接也是如上一样的方法,在此省去分析HTML源码的截图,直接贴上代码: select = page.getHtml().xpath("//div[@class='dw_page']"); urls = select.links().all(); 这里需要注意的是,要防止添加空白搜索结果页的链接,不然将会把整个51job的岗位全都抓取下来。尽管按照定制的抓取逻辑,这种意外不会出现,但还是添加了踢出队列的保护机制,代码如下: Iterator<String> it = urls.iterator(); while(it.hasNext()){ String x = it.next(); if(x.equals("http://search.51job.com/list/000000,000000,0000,00,9,99,%2520,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=")){ it.remove(); } } page.addTargetRequests(urls);