Hadoop 集群环境优化排除错误
来自CloudWiki
一.总体步骤
1.更改主机名
2.yum源配置
3.修改hosts文件
4.关闭防火墙
5.关闭selinux
6.ssh免密配置
7.NTP时间同步
8.Java环境部署
9.Zookeeper环境部署
10.Hadoop环境部署
二.具体实现步骤
1.更改主机名称
hostname set-hostname master
2.yum源配置(根据题目给的地址灵活变通)
vi /etc/yum.repos.d/CentOS.repo
name=Description#一个描述,随意。
baseurl=#设置资源库的地址,可以写阿里云也可以是自己的yum
ftp://
http://
file:///
enabled={1|0}#enabled=1开启本地更新模式
gpgcheck={1|0}# gpgcheck=1表示检查;可以不检查gpgcheck=0
gpgkey=#检查的key;如果上面不检查这一行可以不写
3.根据ip地址配置hosts
vi /etc/hosts 192.168.100.10 master 192.168.100.20 slave1 192.168.100.30 slave2
4.关闭防火墙
systemctl stop firewalld systemctl disable firewalld
5.关闭selinux
vi /etc/sysconfig/selinux SELINUX=disabled
6.ssh免密配置
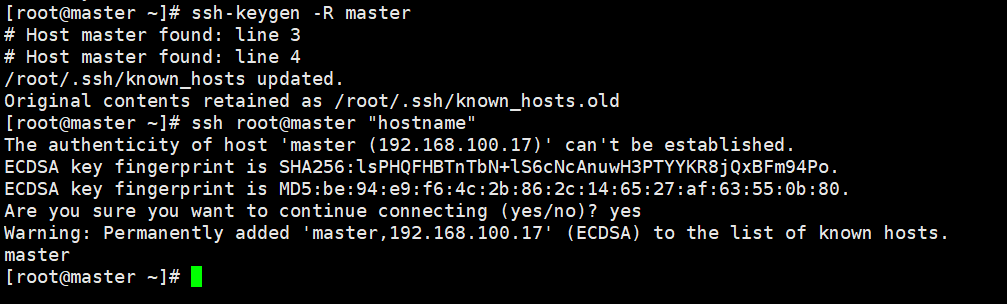
输入 ssh-keygen -t dsa -P -f ~/.ssh/id_dsa 回车 cat /root/.ssh/id_dsa.pub >> /root/.ssh/authorized_keys scp ~/.ssh/authorized_keys root@slave1:~/.ssh/ 将生成文件公钥复制到授权列表 cat .ssh/id_rsa.pub >> authorized_keys 将文件复制到slave中的节点 scp .ssh/authorized_keys root@slave1:/root/.ssh/authorized_keys scp .ssh/authorized_keys root@slave2:/root/.ssh/authorized_keys 排错: 可能会出现ssh生成密码后,修改了hosts文件夹,导致known_hosts文件里面的内容不匹配 原因:ssh会把访问过计算机的公钥(public key)都记录在~/.ssh/known_hosts 当下次访问系统计算机时,OpenSSH会核对公钥,如果公钥不同,OpenSSH会发出冲突警告 解决方案:手动修改Known_hosts内的内容 直接删除known_hosts文件 通过配置~/.ssh/config进行修改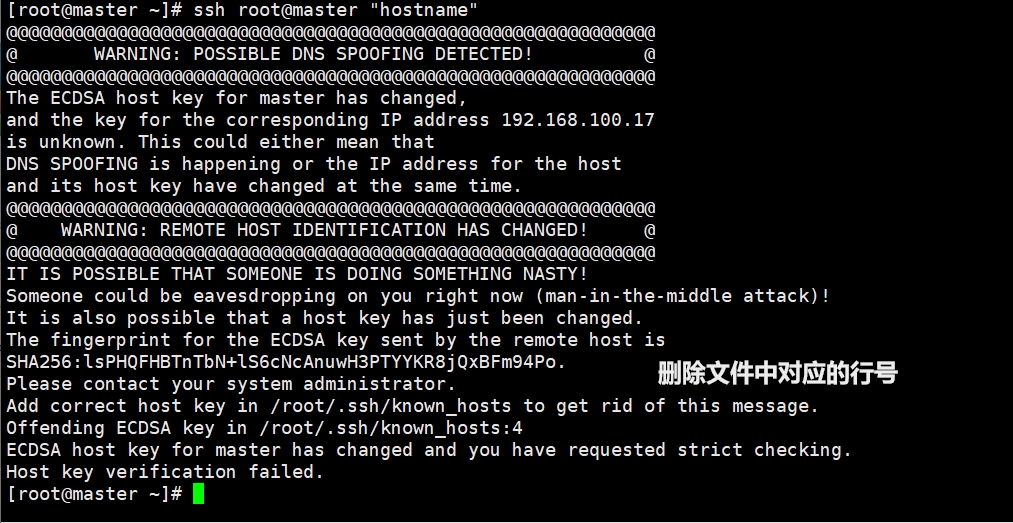


7.NTP时间同步
tzselect 5 9 1 1 将生成的时区配置到/etc/profile yum install ntp -y (主从节点全部安装) vi /etc/ntp.conf #server 0.centos.pool.ntp.org iburst #server 1.centos.pool.ntp.org iburst #server 2.centos.pool.ntp.org iburst #server 3.centos.pool.ntp.org iburst server 127.127.1.0 fudge 127.127.1.0 stratum 10 启动ntp(只启动主节点,不启动从节点) 从节点执行: ntpdate master 完成时间同步
8.Java环境配置
首先将JDK上传到linux中 tar -zxvf jdk.tar.gz -C /usr/java 配置环境变量vi /etc/profile export JAVA_HOME=/usr/java/ export PATH=$PATH:$JAVA_HOME=/bin source /etc/profile 生效环境变量 测试是否成功: java -version
9.Zookeeper环境部署
首先将zookeeper上传到linux中 tar -zxvf zookeeper.tar.gz -C /usr/zookeeper 配置环境变量vi /etc/profile export ZOOKEEPER_HOME=/ export PATH=$PATH:$ZOOKEEPER_HOME/bin 配置zookeeper cd $zookeeper cd conf/ cp zoo_sample.cfg zoo.cfg vi zoo.cfg dataDir=数据目录 dataLogDir=日志目录 server.1=master:2888:3888 server.2=slave1:2888:3888 server.3=slave2:2888:3888 在数据目录中生成myid文件写入对应的server号码 如:master的myid号码为1 启动zookeeper zkServer.sh start 查看zookeeper启动状态 zkServer.sh status
10.Hadoop环境部署
首先将hadoop上传到linux中 tar -zxvf hadoop.tar.gz -C /usr/hadoop 配置环境变量 export HADOOP_HOME=/ export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin hadoop配置文件
hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_171
core-site.xml
<property><name>fs.default.name</name><value>hdfs://master:9000</value></property> <property><name>hadoop.tmp.dir</name><value>/usr/hadoop/hadoop-2.7.3/hdfs/tmp</value></property> <property><name>io.file.buffer.size</name><value>131072</value></property> <property><name>fs.checkpoint.period</name><value>60</value></property> <property><name>fs.checkpoint.size</name><value>67108864</value></property>
hdfs-site.xml
<property><name>dfs.replication</name><value>2</value></property> <property><name>dfs.namenode.name.dir</name><value>file:/usr/hadoop/hadoop-2.7.3/hdfs/name</value></property> <property><name>dfs.datanode.data.dir</name><value>file:/usr/hadoop/hadoop-2.7.3/hdfs/data</value></property>
yarn-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_171
yarn-site.xml
<property><name>yarn.resourcemanager.address</name><value>master:18040</value></property> <property><name>yarn.resourcemanager.scheduler.address</name><value>master:18030</value></property> <property><name>yarn.resourcemanager.webapp.address</name><value>master:18088</value></property> <property><name>yarn.resourcemanager.resource-tracker.address</name><value>master:18025</value></property> <property><name>yarn.resourcemanager.admin.address</name><value>master:18141</value></property> <property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property> <property><name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property>
mapred-site.xml
<property><name>mapreduce.framework.name</name><value>yarn</value></property>
master
master
slave
slave1 slave2